
Olá, pessoal! Tudo bem?
Hoje voltamos ao assunto Well-Architected Framework, e o tema será o Reliability Pillar.
Este pilar nos traz boas práticas referentes a confiabilidade, disponibilidade e resiliência de nosso workload, como suprir um pico na demanda de algum serviço ou ainda como se recuperar de uma falha na infraestrutura, reduzindo ao máximo a percepção desta falha no cliente e/ou usuário.
Princípios de Design
- Testar procedimentos de recuperação: É importante criarmos e validarmos procedimentos de recuperação, para garantirmos a eficiência destes procedimentos, através das facilidades proporcionadas por ambientes de nuvem;
- Recuperação automática de falhas: Com base em métricas e logs extraídos do nosso Workload, podemos identificar quando alguma falha ocorre e, dentro do possível, utilizarmos recursos de automação para sanar o problema automaticamente;
- Disponibilidade com escala horizontal: Um princípio muito importante é evitarmos a existência de apenas um ponto de falha, ou seja, ao invés de mantermos apenas um recurso, aumentando seu tamanho sempre que houver um aumento na demanda, devemos utilizar réplicas deste recurso para evitar que o sistema se torne indisponível diante de qualquer tipo de falha;
- Não tentar adivinhar capacidade: Ambientes de nuvem nos trazem a flexibilidade e agilidade no provisionamento e liberação de recursos, permitindo a adequação do nosso workload à demanda. Por este motivo, podemos monitorar métricas do sistema e provisionar/liberar recursos de forma automática, garantindo a otimização dos mesmos mediante as alterações na demanda apresentada;
- Gerenciar mudanças de forma automatizada: Sempre que possível, devemos automatizar as mudanças efetuadas em nosso workload, para evitar erros humanos e manter a consistência nas configurações.
Conceitos
Antes de entrarmos nos demais tópicos deste assunto, vamos falar brevemente sobre alguns conceitos muito importantes neste pilar: a disponibilidade, alta disponibilidade e tolerância a falhas.
Disponibilidade
A disponibilidade geral de um serviço é definida pelo percentual em que o mesmo estará operando normalmente dentro de um intervalo de tempo (geralmente 1 ano), ou seja, se um serviço possuir uma disponibilidade de 99,99%, saberemos que, em 1 ano, ele poderá estar indisponível por aproximadamente 52 minutos.
Disponibilidade = tempo normal de operação / tempo total
Dependendo dos requisitos de negócio, teremos exigências para níveis de disponibilidade diferentes, onde podemos agregar a disponibilidade de dependências internas do sistema, sistemas externos, etc. Não entrarei em maiores detalhes aqui, mas para saber mais, o guideline deste pilar faz referência a este documento: Calculating Total System Availability.
Alta disponibilidade e tolerância a falhas
Muitas vezes ouvimos que determinado sistema é tolerante a falhas e/ou altamente disponível, e isto nos traz a visão de um sistema que, embora sofrer tais falhas, se mantenha sempre constante, sem apresentar qualquer tipo de impacto aos seus usuários. Apesar desta afirmação ser, de certa forma, verdadeira, existe uma pequena diferença entre estes dois conceitos que deve ser observada.
Um sistema altamente disponível é um sistema que, ao passar por algum tipo de anomalia, irá sim se manter disponível, mesmo que em um estado degradado. Já um sistema tolerante a falhas é um sistema que, ao passar pelas mesmas condições, não sofrerá degradação alguma, e continuará totalmente disponível.
Por ser um requisito mais rígido, um sistema tolerante a falhas tenderá a ter um custo mais elevado, pois o sistema precisará ser resiliente o suficiente para manter o seu estado, mediante a qualquer tipo de falha.
Foundations
Alguns dos pontos mais importantes a serem observados quando modelamos nosso workload, são os requisitos necessários para sua perfeita operação. Nesta área do pilar, são tratados especialmente limites e rede.
Limites de recurso/serviço
Um problema muito comum ao operarmos nosso workload em nosso próprio DataCenter é a escassez de recurso, questões relacionadas a I/O, falta de memória RAM ou CPU, podendo causar sérios problemas e comprometendo a disponibilidade de nossas aplicações.
Na AWS, toda a camada física é gerenciada pela própria, portanto não precisamos nos preocupar com hardware. Contudo, apesar da capacidade computacional da AWS ser, teoricamente, ilimitada, devemos avaliar os requisitos do workload, adequando limites de serviço e modelando de acordo.
Estes limites de serviço, tais como I/O de rede ou quantidade de instâncias em um grupo de auto escala, são impostos para proteger a infraestrutura da AWS, garantindo o nível de SLA mínimo contratado por todos os cliente. Do lado do cliente também são importante, pois evitam custos descontrolados por uma configuração efetuada de forma incorreta. Caso necessário, alguns limites podem ser ajustados, através do contato com o suporte da AWS. Podemos verificar os limites de serviço da AWS aqui.
Devemos sempre trabalhar com alertas e notificações para sermos reportados dos limites que estão próximos de serem atingidos, ou ainda que já o foram, para que possamos tomar as devidas providências, quando possível de forma automatizada. Os serviços da AWS abaixo, auxiliam no gerenciamento destes limites:
- Trusted Advisor: O Trusted Advisor nos fornece uma lista dos limites de serviço da AWS, apresentando de forma clara o atual estado dos limites de serviço de nossa conta na AWS;
- Amazon CloudWatch: O CloudWatch nos permite criar alarmes sobre o estado de alerta dos limites de serviço, possibilitando que sejamos notificados destes estados, e automatizar a resposta aos mesmos, quando possível;
- Amazon CloudWatch Logs: Complementando o item anterior, podemos extrair padrões e insights dos logs do CloudWatch através de filtros, permitindo a extração de métricas e criação de alarmes.

Rede
Outro aspecto importante a ser definido é a topologia de rede. Devemos fazer o planejamento da topologia tendo em mente que nosso workload pode crescer, evitando assim que tenhamos limitações relativas a endereços IP ou ainda que inviabilize a integração com outras VPCs.
Uma das recomendações do Well-Architected Framework ao criarmos uma VPC é utilizar os padrões definidos pela RFC 1918 para definirmos o CIDR (Classless Inter-Domain Routing) da mesma, utilizando blocos CIDRs grandes, e permitindo o crescimento e a acomodação de novos recursos. Além desta, outras recomendações são sugeridas como parte do processo:
- Manter espaço de endereços IP para mais de uma VPC por região;
- Considerar conexões entre contas;
- Deixar espaços de endereço para que múltiplas sub-redes sejam distribuídas entre diversas zonas de disponibilidade;
- Sempre deixar blocos de CIDR não utilizados dentro de uma VPC.
Além disto, devemos planejar estratégias para garantir a resiliência de nossa conectividade, definindo soluções para casos como falhas na topologia, problemas de configuração, variações na demanda, ciberataques (como DDoS), entre outros.
Alguns serviços da AWS podem nos auxiliar nestas definições, como:
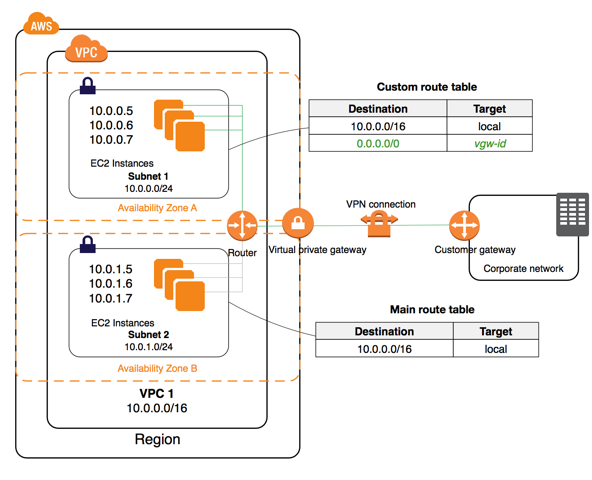
- AWS Direct Connect: Podemos utilizar o Direct Connect para conectarmos a nossa estrutura no AWS com o nosso data center local de forma segura e de baixa latência. Caso necessário, podemos utilizar uma segunda conexão do Direct Connect como backup, ou ainda uma conexão VPN, para garantirmos a comunicação de serviços críticos;
- Amazon EC2: Podemos utilizar instâncias EC2 para executar appliances de VPN, permitindo a conexão entre VPCs ou ainda entre as VPCs e o Data Center local;
- Amazon Route 53: Podemos utilizar o Route 53 como uma camada de defesa contra DDoS (DNS flood), devido a sua escala global e estratégias de resolução de endereços;
- Elastic Load Balancing: Por ser um serviço gerenciado pela AWS, é altamente disponível e permite que criemos uma infraestrutura resiliente, se ajustando a alterações na demanda;
- AWS Shield: O AWS Shield é um serviço da AWS específico para proteção contra ataques DDoS. A sua versão básica já vem ativo por padrão em todas as contas da AWS, porém para existe uma versão Advanced, para aumentar o nível de segurança contra este tipo de ataque.
Por hoje era isso, pessoal! Continuaremos a falar sobre este assunto no próximo post.
Abraços e boa semana!

2 comentários sobre “Well-Architected Framework – Reliability Pillar – Parte 1”