
Olá pessoal, tudo bem?
Como no último post falamos sobre o pilar de confiabilidade do Well-Architected Framework, que trata especificamente de estratégias para tornarmos nossas aplicações mais robustas, resilientes e altamente disponíveis, resolvi escrever um post sobre alguns dos padrões e estratégias citados, apresentando maiores detalhes, que poderemos utilizar para trazer maior resiliência a nível de aplicação.
Retry Pattern
O Retry Pattern é um padrão relativamente simples, que consiste em repetir requisições que falharam, afim de contornar erros transitórios. Para um erro ser considerado transitório, depende muito do contexto e do serviço sendo acessado, mas geralmente são problemas relacionados a comunicação (comum em ambientes multilocatário) e falhas transitórias no serviço destino.
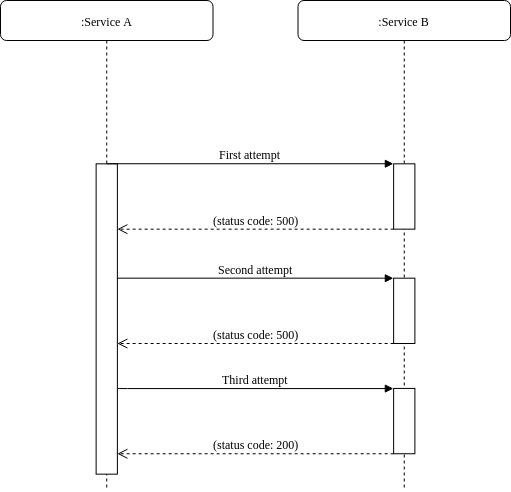
Dependendo do cenário, podemos aplicar diferentes estratégia ao utilizar este padrão:
- Retry imediato: Após uma falha, imediatamente é feita uma nova tentativa;
- Retry com delay: Em caso de falha, e feita uma nova tentativa após um intervalo de tempo pré-determinado;
- Retry com delay incremental: Em caso de falha, é feita uma nova tentativa após um intervalo de tempo pré-determinado, e caso falhe novamente, este tempo de espera é incrementado. Isso acontece em todas as novas tentativas, aumentando o tempo em cada iteração.
Podemos, inclusive, cancelar o retry, caso o erro identificado não seja mais considerado transitório.
Circuit Breaker Pattern
O circuit breaker é um padrão também utilizado para contornar falhas transitórias, mas com um propósito diferente do retry . Enquanto o retry é utilizado para repetir uma requisição que deveria retornar com sucesso, o circuit breaker evita fazer uma requisição que já é sabido que irá falhar. Isso acontece em problemas transitórios que tomam um tempo maior para a sua estabilização, como a queda de um serviço, que pode demorar vários segundos/minutos para se recuperar.
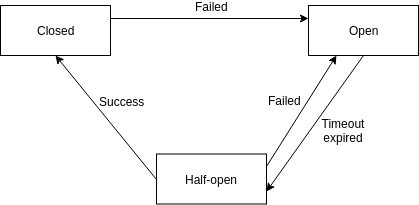
Implementado como uma máquina de estados, ele pode estar nas seguintes situações:
- Fechado (Closed): Indica que está operando normalmente. Caso falhas comecem a acontecer, ele terá o estado alterado para aberto;
- Aberto (Open): Estado de falha, significa que as próximas requisições enviadas, que passam pelo circuit breaker, falharão imediatamente, antes mesmo de serem enviadas ao serviço de destino;
- Meio-aberto (Half-open): Depois de algum tempo (geralmente um timeout configurado), o circuit breaker, em um estado aberto, terá o estado alteado para meio-aberto. Neste estado, será permitida que uma requisição passe, e seja enviada ao serviço de destino. Caso ela falhe, o circuit breaker terá seu estado alterado para aberto novamente. Caso ela execute com sucesso, o circuit breaker terá seu estado alterado para fechado.
Importante: Acima foram citadas algumas condições simples para alteração dos estados do circuit breaker, mas não é uma regra, pois podem ser aplicadas condições mais complexas, como trabalhar com amostragem de requisições para sair do estado meio-aberto ou algum algoritmo mais complexo para identificação de falhas que abrirão/fecharão o circuit breaker.
Compensating Transaction Pattern
Este pattern não foi citado no último post, mas o considero importante, portanto achei interessante tratá-lo aqui também.
Trabalhar com sistemas distribuídos, em algum momento implica também na utilização de consistência eventual, com o intuito principal de aumentar a disponibilidade, resiliência e performance do sistema. Neste cenário, transações de negócio podem iniciar uma cadeia de operações, envolvendo diversos serviços e fontes de dados, que serão atualizados de forma assíncrona.
O grande problema é quando uma operação falha no meio deste processo, sem a possibilidade de regeneração (como um erro de negócio, por exemplo). Neste caso, a transação de negócio ficará em um estado inconsistente, já que foi executada parcialmente.
A transação compensatória serve para resolvermos exatamente este caso. A ideia por trás do pattern é desfazermos o que já foi feito nos passos anteriores, ou ajustarmos de acordo com a necessidade de negócio.
Como citado anteriormente, o ação do undo de um step é sensível ao contexto. Como exemplo, se estivermos falando sobre uma transação de negócio de venda, o primeiro passo (Step 1) pode ser a inclusão de um pedido, e a sua ação de “desfazer” pode ser o seu cancelamento, a sua exclusão, ou o que ficar de acordo com a necessidade do negócio.
Idempotency Token
Operações idempotentes são aquelas que podem ser repetidas diversas vezes, mas apenas a primeira vez aplicada é a que realmente altera o resultado. Em um exemplo simples, poderíamos considerar a operação abaixo como idempotente, pois podemos executar o comando SQL diversas vezes, e o resultado será sempre o mesmo:
MySQL: update users set lastName = 'smith' where userName = 'jack'
Como um exemplo de uma operação não idempotente, poderíamos considerar a execução abaixo, pois a cada execução o valor do salário é incrementado:
MySQL: update employees as A set A.wage = A.wage + 500 where A.Id = 1
Quando falamos em comunicação entre serviços hoje, um dos protocolos mais utilizados é o HTTP/HTTPS. Em uma implementação padrão do protocolo, podemos tirar as seguintes conclusões sobre os principais métodos HTTP:
- GET: É idempotente por natureza, pois não deve atualizar estado, apenas retornar informações;
- POST: Não é idempotente, pois a cada execução um novo item seria inserido, ou ainda determinada operação seria executada novamente;
- PUT: É idempotente, pois atualiza/substitui um objeto inteiro;
- DELETE: Também é idempotente, pois a exclusão será feita apenas uma vez.
Ao menos o POST deverá ser tratado, mas antes de prosseguirmos, devemos definir por que idempotência é importante em um cenário distribuído. Imaginemos o seguinte: temos um serviço A inserindo um item em um serviço B, porém por algum problema transitório, a conexão é perdida, e o serviço A encerra a operação. Para o serviço A, a operação foi finalizada com falha, mas o serviço B pode ter finalizado a inserção do item. Se o serviço A estiver utilizando o Retry Pattern, por exemplo, ele tentará repetir operação, fazendo o serviço B inserir novamente o item.

A ideia por trás do token de idempotência, é enviarmos no cabeçalho da requisição HTTP um token único que será utilizado no serviço destino para reconhecer se a requisição está sendo executada pela primeira vez ou não. Se o token existir no destino (armazenado em cache na memória, ou em algum outro storage como o Memcached ou Redis), e a primeira requisição enviada com ele tiver sido concluída com sucesso, não precisamos executá-la novamente e podemos retornar apenas o resultado, caso necessário.

Wrapping it all up
Esses são apenas algumas dentre diversas estratégias que podemos utilizar para tornar as nossas aplicações mais resilientes e disponíveis. Inclusive podemos mesclar os diversos patterns (retry + circuit breaker + compensating transaction) para chegarmos a uma solução mais robusta.
Contudo, vale ressaltar que cada caso é um caso. A necessidade e configuração de cada um dos patterns citados vai depender muito da natureza do negócio. Porém, na minha opinião, se vamos abraçar as complexidades de sistemas distribuídos, eles são de grande valia.
Por hoje é só pessoal. Espero que tenham gostado!
Um grande abraço e boa semana!
